Introduction
In the fast-paced and high-stakes world of hedge fund investment, data-driven predictive modelling has become essential for firms seeking to gain a competitive advantage. The ability to forecast earnings, assess portfolio risk, and identify market inefficiencies with precision is crucial for capital allocation and investment strategy optimization. Hedge funds managing billions of dollars in assets require real-time, multi-variable financial models capable of adapting to evolving market conditions and uncovering opportunities beyond traditional consensus estimates.
To address these limitations at zeb, we have engineered and deployed an AI-powered predictive modelling system on Databricks, integrating advanced feature engineering, automated forecasting, and scalable machine learning pipelines. This system generates high-confidence financial insights, aligning closely with year-over-year (YOY) performance trends and outperforming traditional forecasting benchmarks. By leveraging Databricks’ unified analytics framework, we provide hedge funds with a dynamic, real-time risk assessment strategy that enhances decision-making and enables a proactive investment approach based on comprehensive financial and behavioral data. While models evolve and improve over time, their performance is entirely dependent on the dataset, making data the true differentiator between an exceptional financial forecasting model and an average one. Ensuring high-quality, diverse, and well-governed data is key to building resilient and adaptive investment strategies.
Continue Reading
Market Risk Assessment
A sophisticated risk assessment strategy must account for both systematic and idiosyncratic risks. Market risk, inherently tied to macroeconomic factors, interest rate fluctuations, geopolitical instability, and liquidity constraints, influences asset valuations beyond firm-specific fundamentals.
Parallel to risk assessment, hedge funds rely on aggregated earnings projections derived from analyst forecasts to inform trading strategies. However, these estimates are prone to inaccuracies due to delayed market reactions, incomplete datasets, and inherent biases in traditional forecasting models.
The core objective of this initiative was to outperform aggregated earnings projections by leveraging proprietary machine learning models trained on a hedge fund’s unique, organization-specific transactional data. Unlike traditional forecasts that rely solely on publicly available financial statements and analyst estimates, our models integrate granular, company-specific metrics sourced directly from the hedge fund’s proprietary data streams. These high-resolution transactional insights, combined with deep fundamental research and proprietary market intelligence, serve as the backbone for predictive modeling, allowing for greater accuracy in near-term earnings forecasts.
This data advantage enables hedge funds to develop differentiated trading strategies, capitalizing on market inefficiencies that are invisible to competitors relying on standard consensus estimates. By incorporating Databricks’ scalable infrastructure, including Delta Lake for efficient data ingestion, Feature Store for standardized feature management, and a suite of ML models steered by Bayesian optimization for adaptive model tuning, we have built a forecasting system that translates unique, proprietary financial insights into superior predictive intelligence. This empowers hedge funds to make faster, more informed investment decisions in a rapidly evolving market landscape.
Architecting an AI-Driven Financial Forecasting System with Databricks
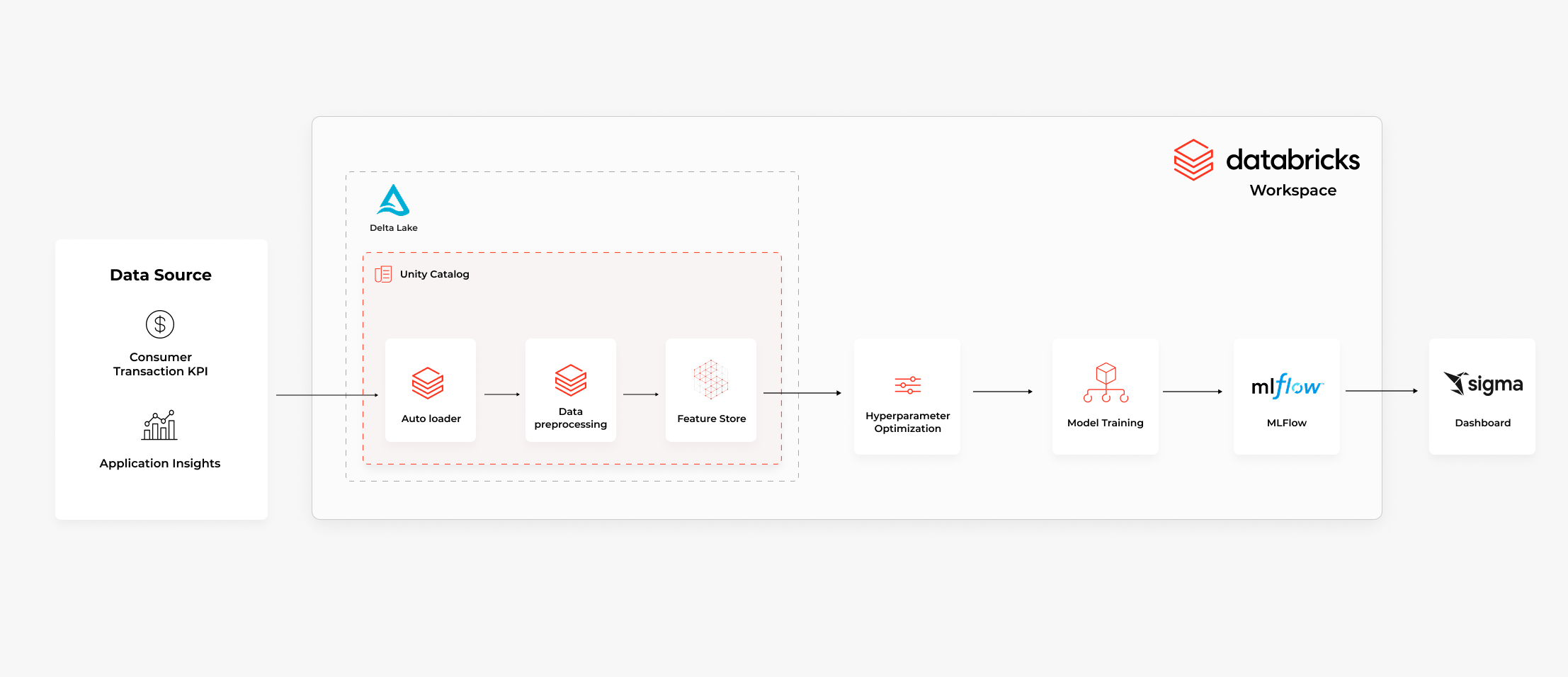
Data Ingestion and Feature Engineering
Given the complexity of hedge fund investment strategies, our solution required a scalable, automated data processing pipeline capable of ingesting, cleaning, and transforming daily financial data from multiple sources into actionable machine learning features. Our pipeline incorporates a robust data preprocessing stage that systematically removes anomalous data points and imputes missing values, ensuring that the subsequent feature engineering works with high-quality, reliable input data.
Scalable Data Ingestion with Databricks Delta Lake
The first step in our architecture was ensuring seamless ingestion and consolidation of diverse financial datasets. The hedge fund’s investment strategy relies on multiple data vendors providing daily earnings reports, real-time market trends, analyst sentiment scores, and transaction-level financial metrics. To efficiently manage both high-velocity streaming and batch data, we implemented Databricks Delta Lake as the foundation of our data ingestion layer.
Key Enhancements with Delta Lake:
- Schema Evolution and Data Quality Enforcement: Delta Lake’s schema enforcement and ACID-compliant transactions ensure that financial data remains consistent, even when vendor data formats evolve over time.
- Optimized Storage and Query Performance: By leveraging Delta Caching and Z-Ordering, we improved query efficiency for feature extraction, enabling low-latency access to historical and real-time financial data.
- Efficient Data Pipeline Orchestration: Integrated Auto Loader and Databricks Workflows to automate ingestion of high-frequency financial feeds, ensuring that our forecasting models are updated with the latest market conditions.
- Robust Data Preprocessing: Once data is ingested through Delta Lake, it undergoes preprocessing to cleanse the data, removing anomalies and imputing missing values, thus establishing a strong foundation for accurate feature extraction.
By utilizing Databricks’ Lakehouse architecture, we effectively integrate data from financial vendors into Delta Lake, governed by Unity Catalog for centralized data governance. The processed data is seamlessly ingested into the Feature Store through AutoLoader, ensuring efficient data management. We then leverage ML models that employ Bayesian optimization to fine-tune model parameters. Once the model is trained and inference is performed, the results are captured and logged using MLflow for transparent tracking. Finally, Databricks Workflows orchestrate the entire pipeline, ensuring smooth execution across all tasks, and the results are fed into a Sigma dashboard, providing valuable insights for decision-making.
- Automated Data Processing with Delta Lake: Our ingestion pipeline, built on Databricks Delta Lake, enables continuous, low-latency data updates, ensuring that the forecasting models always reflect the most current financial landscape.
- Feature Extraction and Engineering: We developed custom feature transformations to capture complex financial interdependencies. These include liquidity ratios, revenue momentum signals, sector-adjusted earnings volatility, and sentiment-based price impact indicators.
By standardizing feature representations within a centralized feature repository, we mitigated data drift risks and inconsistencies across model training and inference environments.
High-Frequency Model Training and Adaptive Learning
Unlike conventional forecasting models trained on static historical data, our approach employs continuous learning cycles, wherein models ingest new financial information daily, refining predictions in real-time.
- Rolling 90-Day Forecasting Framework: Our system dynamically forecasts earnings over a rolling 90-day horizon, ensuring alignment with the latest market movements.
- Daily Model Retraining and Optimization: The training pipeline incorporates both actual and forecasted financial data, enabling the model to self-correct based on discrepancies between predicted and realized earnings.
- Multi-Model Ensemble Strategy: Rather than relying on a single predictive approach, we trained multiple specialized models across different sectors and market conditions, selecting the most performant architecture dynamically.
- Hyperparameter Tuning for Better Performance: Leveraging our proprietary pipeline for ML models, we automated feature selection and preprocessing to optimize input variables for predictive stability. In addition, by applying Bayesian optimization for hyperparameter tuning, we significantly improved model accuracy and ensured robust generalization across diverse market conditions
This approach delivers highly responsive, dynamically adaptive forecasting models, equipping hedge funds with predictive intelligence that evolves in tandem with market fluctuations.
Feature Store Integration for Model Consistency
A key differentiator of this solution is its integration with Databricks Feature Store, ensuring predictive models utilize consistent, validated feature sets across training and inference cycles. This structured approach has led to a 20% improvement in model performance by minimizing data inconsistencies and optimizing feature management.
- Centralized Feature Management: Standardizes critical financial signals across multiple predictive models, reducing computational overhead.
- Automated Feature Updates: Dynamically recalibrates features as new data arrives, eliminating the risk of outdated or misaligned model inputs.
- Cross-Model Feature Reusability: Facilitates interoperability, enabling various forecasting models to leverage shared feature repositories without redundant engineering efforts.
By governing feature consistency and automating updates, this structured feature architecture enhances model interpretability, reproducibility, and reliability, leading to better forecasting accuracy across different market scenarios.
Model Lifecycle Management with MLflow
To operationalize and monitor model performance at scale, we integrated MLflow, establishing a structured end-to-end model governance framework.
- Experiment Tracking and Performance Benchmarking: Logged key forecasting metrics (Mean Absolute Error, RMSE, and SMAPE) to systematically evaluate model effectiveness.
- Model Registry and Versioning: Maintained a secure, version-controlled repository of production models, enabling traceable deployments and seamless rollbacks.
- Automated Deployment and Model Drift Detection: Integrated real-time monitoring to assess model stability, triggering automated retraining when performance degradation is detected.
By standardizing model tracking, deployment, and evaluation, MLflow ensures that the predictive framework remains robust, transparent, and continuously optimized for evolving financial conditions.
Scaling Model Execution and Performance Optimization
To achieve high-frequency model execution at scale, we designed a distributed computational architecture that can be retrained and inferenced at scheduled daily intervals.
- Parallelized Data Processing: Implemented distributed computing on Databricks clusters, significantly reducing feature extraction and model execution latency. Utilized PySpark and serverless compute, which played a huge role in reducing computation time from 1.5 hours to 30 minutes, directly reflecting on cost savings.
- Optimized Cluster Scaling: Dynamically adjusts compute resources to handle fluctuating data volumes, ensuring cost-efficiency.
- High-Throughput Model Execution: Trained and validated 50,000+ models daily, completing the full execution pipeline within 30 minutes.
This performance optimization ensures that hedge funds can continuously refine trading strategies without operational bottlenecks.
Strategic Business Impact
The implementation of this AI-driven forecasting system has delivered substantial strategic advantages, enabling hedge funds to:
- Achieve superior earnings prediction accuracy, systematically outperforming consensus estimates.
- Enhance risk-adjusted returns by identifying undervalued and overvalued assets with greater precision.
- Transition from reactive to proactive investment strategies, leveraging ML-driven insights for optimal capital allocation.
This transformation underscores the critical role of advanced machine learning in hedge fund investment strategy, shifting risk assessment from a retrospective analytical process to a predictive, forward-looking discipline.
Strategic Reflections
The integration of machine learning, automated feature engineering, and scalable predictive modeling represents a fundamental shift in hedge fund risk management and earnings forecasting. By leveraging Databricks’ unified analytics platform, including Delta Lake for high-performance data ingestion, Unity Catalog for centralized data governance and security, the Feature Store for standardized and reusable financial indicators, ML models optimized via Bayesian optimization for precise hyperparameter tuning, MLflow for end-to-end model lifecycle management, and Databricks Workflows for orchestrating complex pipelines,we have built a highly scalable, intelligent forecasting framework.
By integrating advanced technical solutions with deep business expertise, zeb empowers fintech companies to achieve unprecedented levels of operational efficiency, predictive accuracy, and real-time decision-making. This synergy between state-of-the-art technology and sophisticated financial analysis fosters more resilient, adaptive, and proactive investment strategies. As Databricks continues pushing the boundaries of AI-driven financial analytics, hedge funds and fintech firms remain well-positioned to navigate market complexities and drive superior investment outcomes in the future of the financial industry.
