Our recent article sparked quite a reaction from employees at a certain data enterprise company (❄️👀). Since there’s so much buzz around this, let’s break it down with some data.
When evaluating data platforms, the core question isn’t just about features—it’s about priorities. One platform (🚀) drives innovation with a strong engineering focus, while the other (❄️) leans heavily on sales. One offers fine-grained access control and dynamic AI monitoring, while the other relies on more traditional models. The difference shows in everything from security and governance to scalability and performance.
Databricks dedicates around half of its workforce to product development and technological leadership, reinforcing its focus on engineering-driven innovation. In contrast, ❄️ allocates a lesser of proportion of its workforce to engineering, placing a stronger emphasis on sales and market expansion.
Continue Reading
Security & Access Control: Fine-grained RBAC & ABAC vs. limitations in attribute-based controls.
- Detailed Control Levels: Unity Catalog in Databricks offers both role-based access control (RBAC) and attribute-based access control (ABAC) for fine-grained security, outperforming platforms like ❄️.
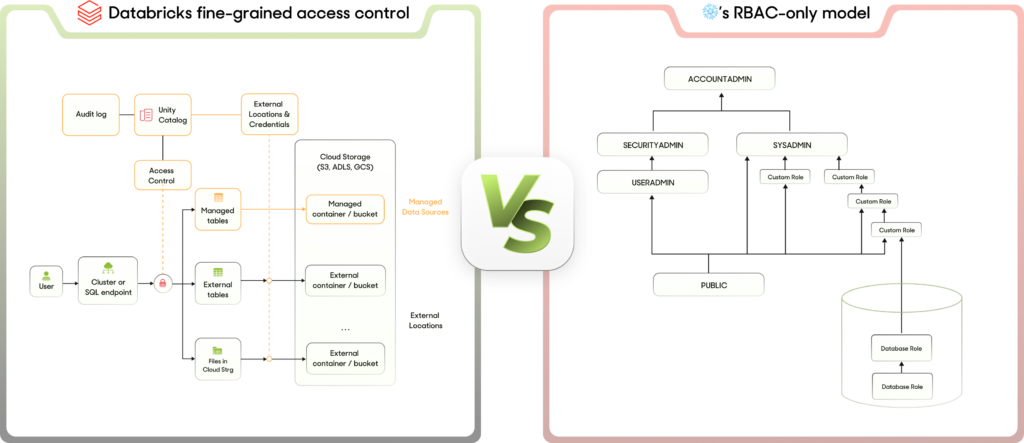
- Comprehensive Management: Databricks manages user groups and metadata seamlessly, ensuring stringent access controls based on specific user roles and attributes.
- Regulatory Compliance: Robust governance frameworks like Unity Catalog help businesses stay compliant with evolving data protection regulations, preventing legal issues and ensuring data integrity. By automatically analyzing data attributes and their nature, it recommends masking or security controls for PII data.
- Dynamic Access Control Management: Databricks inherits access policies from cloud providers, aligning them with user behavior and data sensitivity to ensure consistent access control across the data infrastructure—going beyond static, role-based models with limited attribute controls.
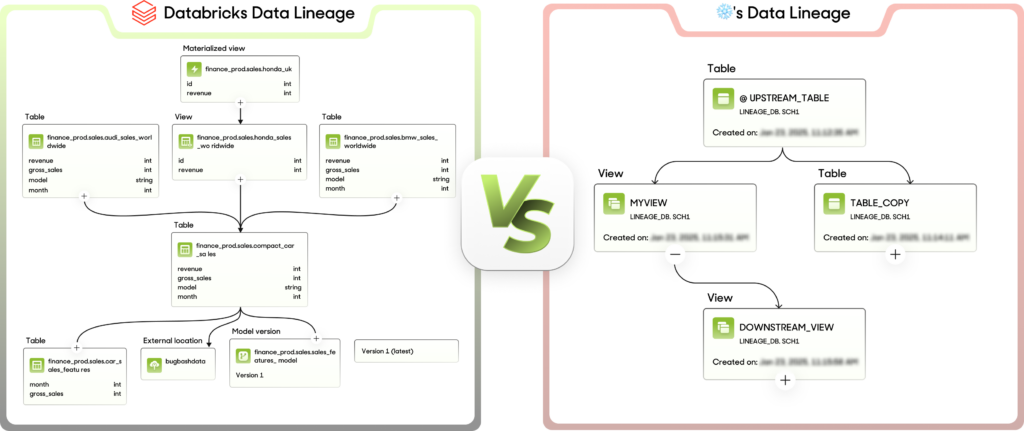
- Transparent Data Lineage: With Unity Catalog, data lineage is available by default and offers enhanced, fine-grained visibility across queries, notebooks, ML models, and more. In contrast, ❄️ provides data lineage only in the enterprise edition or higher, with a limited graph showing only source and target relationships.
AI Monitoring & Data Quality: Proactive detection vs. reactive fixes—crucial for AI reliability.
- Model Readiness Assurance: Databricks proactively identifies model biases and potential data anomalies, guaranteeing that AI models are trained on highest quality data for real-world readiness and effectiveness.
- Automated Data Hygiene: Advanced algorithms in Databricks detect and cleanse subpar data, an automated approach that far exceeds the manual, reactive data fixes still common in some AI systems.
- Real-Time Drift Detection: Lakehouse Monitoring in Databricks offers real-time detection of data drift, a capability that significantly reduces latency in decision-making adjustments compared to competitors.
- Data Quality Forecasting: With predictive insights into potential data quality issues, Databricks permits forward-looking preparation, a stark contrast to platforms that only react post-event.
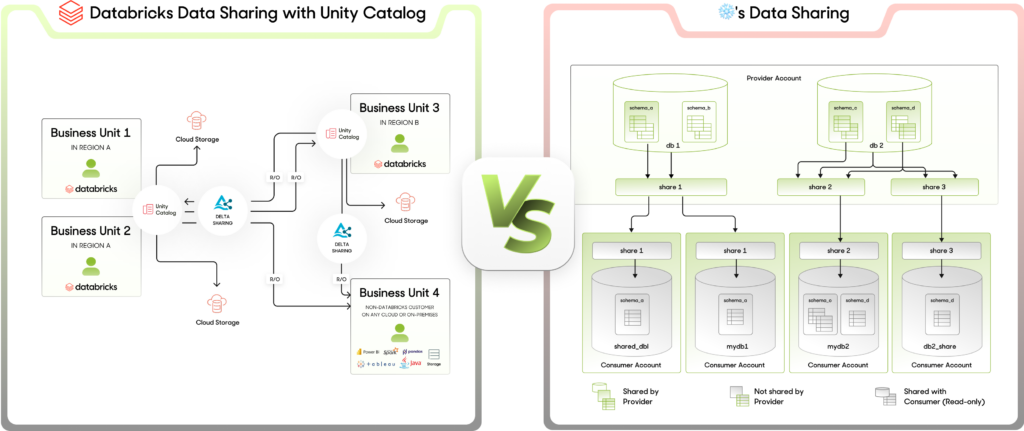
- Governance-First Approach to Shared Data: Databricks ensures that data shared externally with partners and third parties retains its governance policies, extending data integrity beyond the confines of the original platform—a rare feature in data sharing.
Scalability & Flexibility: Handling unstructured AI data seamlessly vs. requiring extensive preprocessing.
- Flexibility in Data Handling: Databricks efficiently handles large-scale data with auto-schema inference, leveraging Spark’s distributed computing. Conversely, ❄️’s nested data processing is slower and requires explicit schema handling, leading to higher costs.
- Scalability: Databricks enables automatic dynamic scaling of clusters based on workloads, ensuring efficient resource usage. Whereas ❄️ allows compute scaling independently but lacks fine-grained control, often requiring manual resizing.
- SQL Support: Databricks supports ANSI SQL and PySpark, offering more flexibility for diverse analytical needs, making it easier for users. On the other hand, ❄️ Snowflake strictly adheres to ANSI SQL, which is advantageous for traditional SQL users but less flexible.
- Storage & File Handling: Databricks supports a broad array of file formats including Parquet, Delta, JSON, ORC, and Avro natively, with best-in-class Delta Lake support for lakehouse architectures. ❄️ also supports Parquet, ORC, and JSON but processes them in a proprietary format and offers limited direct Delta Lake support, making it more suited for traditional data warehouses.
Performance & Efficiency: AI workloads run up to 1.5x more cost-efficiently on one platform than the other.
- Complex Transformations & Aggregations:Databricks harnesses Spark DAG’s optimization for advanced large-scale transformation handling, while ❄️is suitable for structured queries but can stumble with complex, large transformation.
- Data Processing Velocity: Databricks aces complex transformations by leveraging distributed compute capabilities, making it 20% faster than ❄️, which tends to be slower due to row-by-row processing.
- Caching & Efficiency: Databricks improves performance with features like Delta cache and adaptive query execution, whereas ❄️’s result caching falls short in advanced transformation caching.
- Optimized Workloads: Databricks is fine-tuned for diverse workloads, including batch, streaming, and running ML models, ensuring robust concurrency for heavy ETL tasks. Contrastingly, ❄️ excels in BI workloads but may falter under high transformation demands.
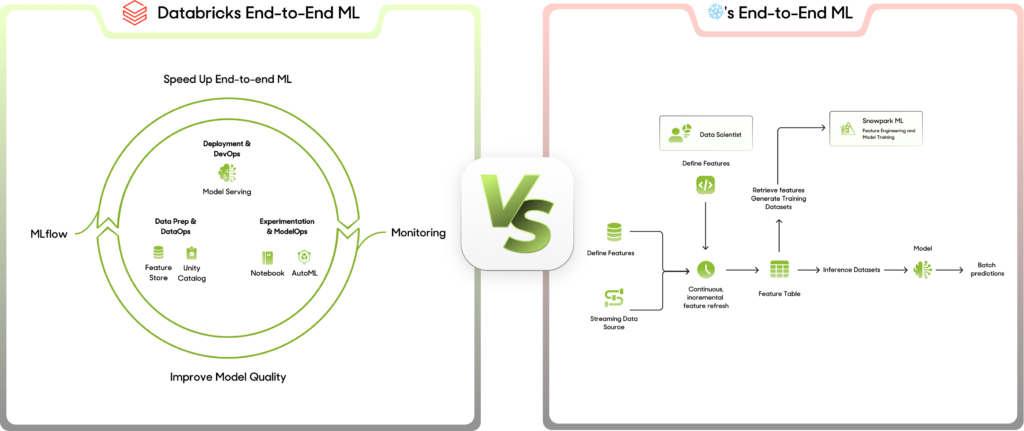
- Enhanced AI & ML Performance: Databricks leads in AI and ML workloads, utilizing distributed Spark computing, GPU acceleration, and AutoML features to optimize model training and deployment. With its auto-scaling clusters, compute costs consumption is less, offering up to 1.5x more cost-effectiveness. In contrast, ❄️’s manual warehouse scaling incurs higher costs for extended ML tasks.
At the end of the day, the choice between Databricks and ❄️ comes down to priorities. As the data space continues to evolve, the choice between engineering-driven innovation and sales-driven expansion becomes increasingly clear. If the goal is cutting-edge AI-driven data management, fine-grained security, and real-time scalability, Databricks stands out.
But making the most of Databricks requires the right approach. With deep industry expertise in Databricks and modern data architectures, zeb helps organizations maximize the platform’s full potential—whether it’s optimizing performance, enhancing governance, or streamlining AI workloads. Instead of navigating the complexities alone, partnering with zeb ensures your data strategy is built for efficiency, security, and long-term success.
Ready to take your data infrastructure to the next level? Let’s talk.
